
In my previous posts of confidential computing I have talked about
1) Introduction to Confidential Computing - Part 1
2) Architecture of confidential computing - Part 2
3) Enarx Demo : Confidential Computing - Part 3
4) Zero Knowledge Proof : Confidential Computing - Part 4
In this demo I will be demonstrating, Machine learning model and running it in Enarx dev environment.
So, model will help us in predicting whether the person has diabetes or not. It will take in consideration different factors such as Pregnancies, Glucose, Blood Pressure, Skin Thickness, Insulin, BMI, Diabetes Pedigree Function and age.
Diabetes is a chronic condition in which the body develops a resistance to insulin, a hormone that converts food into glucose. This demo intends to create a model using a decision tree algorithm on the PIMA Indian Diabetes dataset to predict if a particular observation is at risk of developing diabetes, given the independent factors.
The decision tree Algorithm belongs to the family of supervised machine learning algorithms, it can be used for both classification problems as well as for regression problems. It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node represents the outcome.
A decision tree for the regression algorithm was created and the dataset was split into training and testing sets.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)
We import the train_test_split function from Sklearn model selection for splitting data arrays into two subsets: for training data and for testing data.
Sklearn (or Scikit-learn) is a Python library that offers various features for data processing that can be used for classification, clustering, and model selection.
Model_selection is a method to analyze data and then use it to measure new data.
In this demo, the workload (model and dataset) will be deployed to the TEE using Enarx, and the model will be trained using the dataset in the TEE which ensures confidentiality and integrity.
We can start with creating the decision tree so that we can try to predict the classification of whether the patient is diabetic or not. To this end, the first thing to do is to import the DecisionTreeClassifier from the sklearn package.
from sklearn.tree import DecisionTreeClassifier
The next thing to do is then to apply this to training data. We then fit the algorithm to the training data:
We want to be able to understand how the algorithm has behaved, and one of the positives of using a decision tree classifier is that the output is intuitive to understand and can be easily visualized.
We see how it performed on the training data as well as on unseen test data. This means we have to use it to predict the class from the train and test values, which is done using the predict() method.
Environment setup
- Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
- Wastime
curl https://wasmtime.dev/install.sh -sSf | bash
For demonstrating this, I have used Diabetes-demo
Follow these steps :
git clone https://github.com/jnyfah/Enarx-Demo
cd Enarx-Demo
cargo build
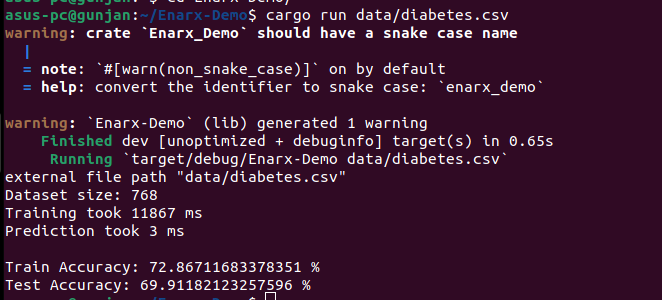
cargo run data/diabetes.csv
Measuring performance:-
The total time to train the model was - 84.85 sec whereas the prediction time was only 2ms.
We measure the accuracy score which is the fraction of true positives and true negatives over the total number of assigned labels.
We see the training accuracy is 72.86% and the Test Accuracy is 69.91% (Obviously we can improve the model accuracy by fine-tuning & choosing appropriate Algorithms and functions)
Your output should look like this
Now, next step would be to compile it to wasm which can be done by
rustup target add wasm32-wasi
cargo build --release --target=wasm32-wasi
We should now have the WebAssembly module created in target/wasm32-wasi/debug
Now, we have to execute it in wasmtime run environment
wasmtime --dir=. target/wasm32-wasi/release/Enarx-Demo.wasm data/diabetes.csv
Your output will be displayed as same as above.
References
Github ML Demo
Happy Hacking!!





Top comments (2)
good job @gunjan_0307 writing this blog. I got confuse while reading the blog that on what basis or data this model is being executed as I was not able to find any sample input and how it can be used by an end user. Can you please elaborate about the same and help me out with that?
The model is executed on the PIMA Indian Diabetes Dataset, it is feed as the input in the model. This is demo that only shows how to implement ML Model on the Enarx dev environment, not how to train the ML Model. Please feel free to DM me, for detailed explanation.